Udacity上看了Apollo的course,正好又在GTC看了一些自动驾驶肌肉秀。既然是要做AGV,自动驾驶当然是要学习的。
Apollo的架构
- 定位:
- RTK(real time kinematic):GPS+IMU
- 多传感器融合:GPS+IMU+激光雷达
- 感知:
- input:雷达数据,图像数据,雷达传感器校准外部参数,前摄像机标定的外部和内在参数,车辆的速度、角速度。
- output:
- 具有航向、速度、分类信息的三维障碍轨迹
- 车道标志信息具有拟合参数、空间信息以及语义信息
-
预测:
针对障碍物的运动预测,输入障碍物与定位信息,输出具有预测轨迹的障碍物 -
路由:
输入地图数据,路由请求(始终点),输出路由导航信息 - 规划:
- input:定位、车辆状态、地图、路由、感知、预测
- output:安全舒适的轨迹,交由控制器执行
- 控制:
- input:规划轨迹、车辆状态、定位、DW自动模式更改request
- output:底盘控制命令(转向、节流、刹车)
这将自动驾驶的工作流根据功能、场景和level做了很好的解耦。虽然在实际搞自己的work时不一定要按照这种架构,但是按上面的划分思想,把当前问题工况划分到类似的某一个模块中,可以帮助理清与问题上下文之间的联系,或者更好理解问题本身。
AVG目前由于算力有限且场景规则化,基本只进行定位->控制的workflow,路由与规划交由调度系统完成。如果要加入货架车道线保持,则可以放入感知模块,这样车道线保持与其他现有模块、上下位机的交互就可以follow这个架构下感知与其他模块交互的模式。
其他
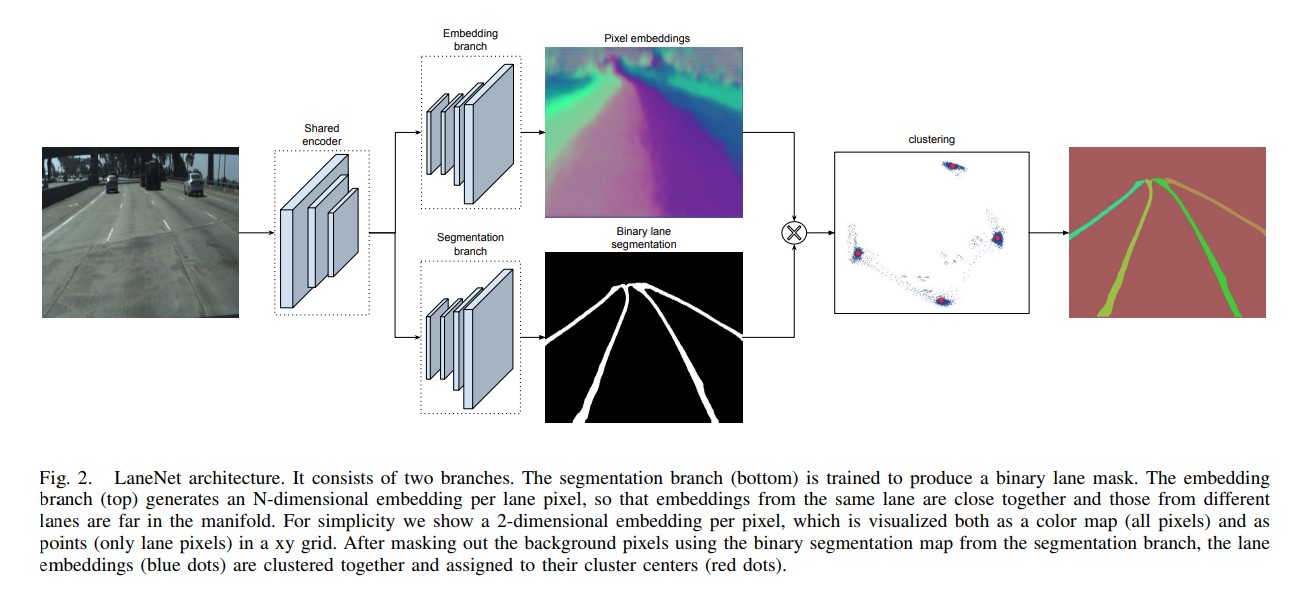
LineNet,车道线检测
先进行segmentation,将图像分割为车道和背景,再通过embedding把分割后的的车道分离为车道实例。
DriveNet
TODO
VSLAM
典型的VSLAM包含四个部分:
-
Visual Odometry:估计两个时刻间机器人的相对运动量。激光SLAM中因为可以直接得到有距离信息的全局地图所以只需要把当前位置在地图中匹配。
对于VO特别是mono VO,主流采用基于特征的方法:提取特征(如角点),根据特征Map的匹配求解相机姿态。特征点通过描述子(descriptor)进行描述,描述子为特征点与周围领域的信息。
实际中,一般先用代数方法求粗略解,再用bundle adjustment进行优化。

-
后端:为了估计累积误差,较早的方法将SLAM构建成卡尔曼滤波,最小化运动方程与观测序列之间的噪声,迭代求解。现在采用 Bundle Adjustment 方法,把误差平均到每一次观测。
-
建图:TODO
-
回环检测:机器人识别曾经到过的场景的能力。普遍采用词袋模型进行回环检测(将视觉特征聚类,建立词典,)
预处理
-
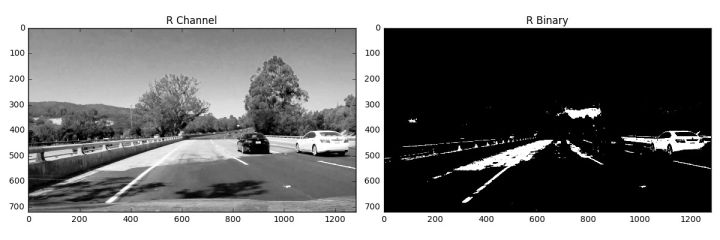
RGB颜色空间与HLS颜色空间可以对同一张图表现出不同的特性:


- Hough变换:识别图像中几何形状的基本方法。将几何形状通过曲线的表达形式映射到参数空间,将问题从全局的曲线检测转换为参数空间局部的峰值检测。